Why using asynchronous communications?
TL;DR: this blog post explains the status of async communications
It all started when I watched a video online: Scaling Server Software at Facebook. The video gives interesting details used at facebook to optimize their systems. One of the big advice (among many others) is to use asynchronous communications. I wanted see the benefit of using asynchronous communication and how it compares with the traditional synchronous model.
This blog post explains first the different between synchronuous and asynchronuous I/O, presents the programming models and gives some rough estimates of what you can expect. If you develop a massive ditributed system, you cannot avoid asynchronuous communications.
Synchronous vs. asynchronous I/O
Let’s first start by explaining what is the difference between synchronous and asynchronuous
communications. A distributed application communicate by performing I/Os (Input/Output). It can
be network communications (socket), reading/writing into a file, etc.
In the UNIX/
POSIX world, I/O are performed
on file descriptors (FDs): when you open a file or a network communication,
you open a file descriptor and can then perform read() or write() operations on it.
You have two ways to perform I/Os: synchronously and asynchronously. When using synchronous I/O, the caller is block until the call succeeds. When using asynchronuous, you are periodically checking if there is anything received. The next sections details these two worlds.
The synchronous world
In the synchronous world, you wait for a reply. For example, if you call read() on a network socket,
your current program will wait until some data is available.
This communication pattern is very similar to a phone conversation: you talk first and then, wait for a reply from the other side.
Synchronous communication are very sequential. Most of the time, you perform a series of operations as follow:
- Open the communication channel (e.g. take your phone and dial your friend)
- Do several exchanges (e.g. each person talks and wait for the answer of the other person)
- Close the communication channel (hangup)
This model is fine when you have one communication happenning. The problem is when your application is massively distributed and communicate with a lot of peers. In that case, you need to have N tasks (also called threads) and each one will take care of communicating with one peer.
The following pseudo-code shows a very common way to implement such a system: create a threads for each request and let it handle one communication.
void loop ()
{
send_request();
wait_for_reply();
process_reply();
}
void main ()
{
for (int i = 0 ; i < NREQUESTS ; i++)
{
create_thread (i);
}
for (int i = 0 ; i < NREQUESTS ; i++)
{
wait_for_thread (i);
}
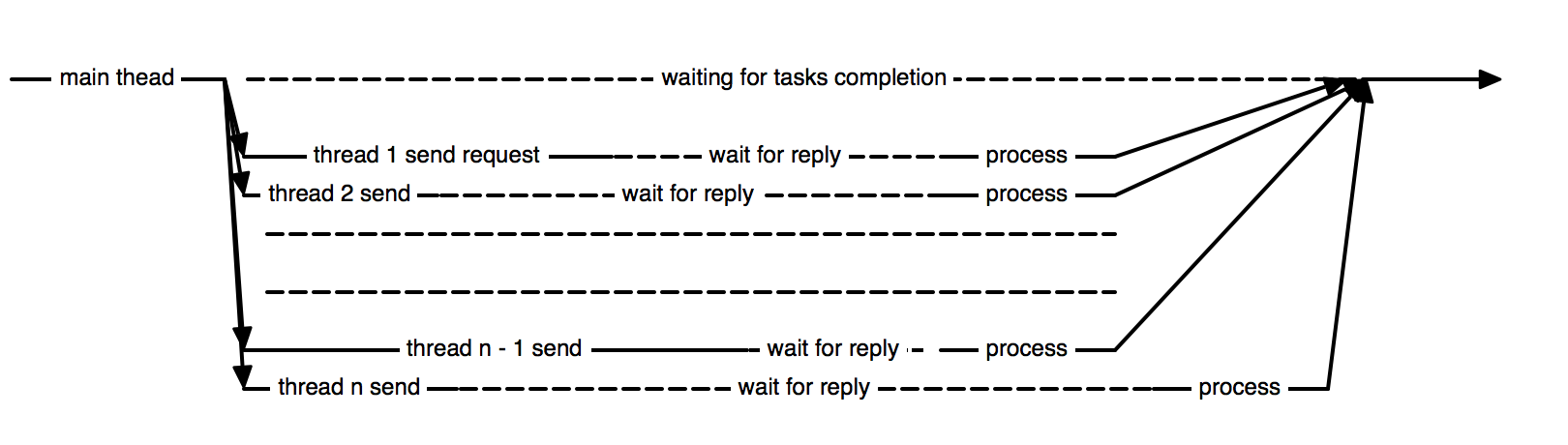
}The execution diagram is as follow: the main thread creates one thread for each communication patterns and wait that all of them finish their work. In that model, the operating system schedules the threads and activates them when the data is available, adding more data structure into the kernel.
One can note that after sending the request, a thread is waiting for the reply, doing nothing but waiting for incoming communication.
The asynchronous world
In the asynchronous world, the program post operations and check the result later. This communication model is similar to text messages: you send a text but does not wait for an immediate return, the reply may arrive now or hours later. The key here: you do not have to stay on the line and wait for a reply, you can check it later.
Asynchronous communication are not sequential at all. In fact, you send some information (text messages) and then, there is a main loop that receives replies and write back according to a protocol.
There is no need for additional task in that model, you can handle all of them in the main task. The hard part is to follow the status of each operation.
The following pseudo-code shows a common approach to do asynchronuous communication. The most important aspect of the main loop that handles new events.
void main ()
{
for (int i = 0 ; i < NTHREADS ; i++)
{
send_request (i);
}
int completed = 0;
while (completed < NREQUESTS)
{
event = wait_for_event();
process_event();
completed++;
}
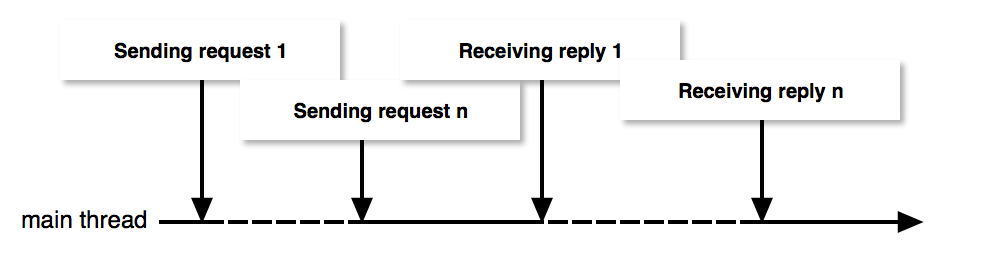
}The following diagram shows an execution trace of asynchronuous communication. There is no new task, the main tasks posts all operations to do in the beginning and check their status. Once all operations returned, the program is complete. Note that replies are not coming back in a specific order.
Why using asynchronous communications?
There are two majors issues with synchronous communication:
- Lot of time of threads consists of waiting for I/O completion. It is a waste of resources
- It introduces overhead, especially in the kernel for managing/scheduling/dispatching resources.
By using asynchronuous communication, you just avoid resources waste and then, can process more requests with the same hardware. If your system is massively distributed, and handles thousands of simultaneous connections it will either (1) saves resources or (2) process more requests.
If you are not convinced, I suggest watching the video Scaling Server Software at Facebook, a simple 5% of memory or processor usage reduction means savings in the scale of thousands or millions of dollars. There are more information about asynchronous communication use at facebook on their blog).
To summarize, using synchronous programming is easily and straightforward but does not scale for massively large, distributed system. Asynchronous programming makes your progrma more complex but avoid bottlenecks and resources overhead.
Comparing sync and async performance
In order to evaluate the performance difference between synchronous and asynchronous communications, I wrote a small client program that starts N connections to a server and print the result. Basically, the program initiates a fixed number (N) of HTTP connections to a web server, get a page and prints it on the standard output. I wrote two variants of the program:
- Synchronous: each connection is using a thread that opens a socket, write the request and print the result. There are then N threads, N being the number of connections.
- Asynchronous: the main program opens N sockets and handle them in a main control loop.
In order to verify that each program retrieves the same thing (e.g. they return the same output), I log the output in a file and compares the file with diff. Results were the same.
I ran the tests on the following configuration
- Linux kernel 4.9
- CPU Intel(R) Core(TM) i5-3320M CPU @ 2.60GHz
- 8GB RAM
Finally, to remove the variability factor of the latency, all requests are issued to a local host. I started by just running the program and vary the number of connections issued to see I then varied the number of concurrent connections between 1 and 100 and capture the system time used. The system time is the time spent in kernel mode. It is clear that when using threads, there is an overhead of resources management for the kernel.
The following picture show the time spent in kernel mode for each version of the program (X=#connections and Y=time spent in kernel mode).
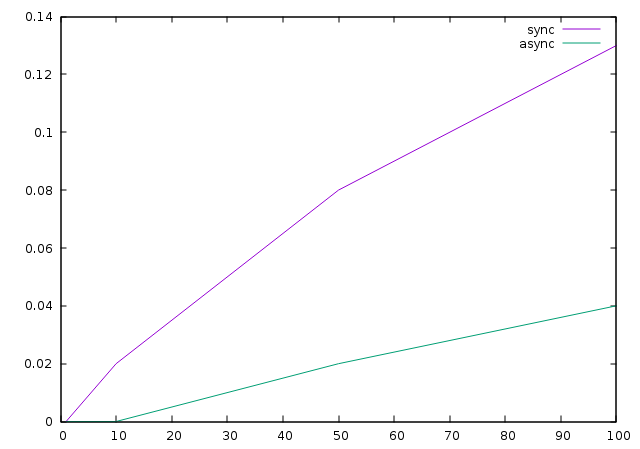
These results are very limited - this is done on a single host that communicates with only another machine without additional load. One can expect more impact when using threads, especially when using locks/mutexes with more load.
A note on POSIX async
When starting this work, I was looking for POSIX functions to perform async communications. As POSIX is the reference for programming on UNIX system, this was natural to look how it handles asynchronuous communications. Unfortunately, the asynchronuous API is a real disaster, in terms of its definition (for example, it uses threads or signals to handle incoming data - something to just avoid) or implementation (done in userland in Linux, which leads to poor performance).
Other people also reported also discusses this. I have no idea why the current POSIX async API is so bad and why they published such a useless framework: the notification mechanism (signals or threads) is inefficient, counter-productive and counter-intuitive. I have no idea what the POSIX committee members were smoking the day they approved this.
The result is that today, each UNIX has now its own implementation of asynchronous communication management (epoll for linux, kqueue for BSD leaving developers with no option than developing non-portable code.
Where you go from there?
No question about it, asynchronous communications are definitively the way to go if you are developing a massive distributed system.
So how to use asynchronous communication effectively with your favorite programming language? There are multiple frameworks available:
- For C++, boost includes asynchronous communication functions
- For Python >3.4, the asyncio framework provides everything you need to manage asynchronous communication
- For Python <3.4, you have existing framework as detailed in The Hacker’s guide to Python - you can also learn more in this youtube video
- For pure C on linux, use directly epoll. This is not portable to any other UNIX but I bet you might not migrate to any other system now.
Code used for evaluate sync/async performance is available online.